When people talk about scaling APIs, the conversation often jumps straight to infrastructure.
More servers.
Load balancers.
Caching layers.
Queues.
Databases.
All of those things matter.
But before infrastructure becomes the bottleneck, many APIs run into a simpler problem:
the application itself was not designed to stay efficient under load.
That usually shows up as:
- heavy controllers
- repeated database queries
- too much work happening inside the request cycle
- poor validation boundaries
- expensive responses
- inconsistent module design
- logic that becomes harder to optimize because responsibilities are mixed together
In other words, performance problems are often architecture problems first.
That is why scaling an API is not only about adding hardware. It is also about building an application that can handle growth without falling apart.
If you are using Assegai, the good news is that its structure already pushes you in a useful direction.
Modules, controllers, providers, DTOs, queues, and clear feature boundaries are not just “nice architecture.” They are also the building blocks of APIs that stay manageable when traffic increases.
This article walks through practical best practices for scaling Assegai apps for high-traffic workloads.
1. Keep controllers thin
This is one of the simplest rules, and also one of the most important.
Controllers should handle transport concerns:
- receiving the request
- binding params, query, or body data
- handing work off to a provider/service
- returning the response
That is it.
When controllers become too smart, they start doing work that is harder to reuse, harder to test, and harder to optimize in one place.
For example, a controller should not be responsible for:
- assembling complicated domain logic
- running several database operations directly
- performing large transformations
- deciding caching policy inline
- triggering multiple downstream side effects
In a small app, that might feel convenient.
In a high-traffic API, it becomes expensive because the request path turns into a pile of work that is hard to isolate and improve.
A thin controller gives you a better scaling surface because the real work lives in a service/provider where it can be optimized intentionally.
2. Put business logic in providers/services
When an API starts getting real traffic, one of the first things you want is the ability to optimize behavior without rewriting the transport layer.
That is much easier when the business logic lives in providers/services.
Why?
Because providers/services can be:
- profiled more easily
- reused by more than one endpoint
- tested in isolation
- cached or wrapped more cleanly
- refactored without changing route structure
A well-placed provider lets you improve performance where the work actually happens.
For example, if an endpoint becomes slow, you want to look at one clear service method and ask:
- are we making too many queries?
- are we doing repeated computation?
- should part of this move to a queue?
- should this result be cached?
- are we loading more data than we need?
That is much easier to answer when the application has a clean service boundary.
3. Validate early and fail fast
High-traffic APIs cannot afford to waste work on invalid requests.
One of the easiest wins is to validate data as close to the request boundary as possible.
That is where DTOs and validation rules become important.
If the request is malformed, incomplete, or obviously invalid, the application should reject it early instead of pushing it deeper into the system.
That gives you several advantages:
- less wasted processing
- fewer unnecessary database calls
- clearer error handling
- more predictable service behavior
This is not only about speed. It is about protecting the more expensive parts of the app from bad inputs.
In practice, the earlier invalid requests are stopped, the better your app behaves under real-world load.
4. Be selective about what you return
A surprisingly common performance issue is simply returning too much data.
APIs often slow down because responses become heavier than they need to be.
Common causes include:
- returning full objects where summaries would do
- loading related data by default
- sending large payloads for list endpoints
- formatting more data than the client actually needs
The fix is not “make the server faster.”
The fix is often:
return less, more intentionally
For list endpoints especially, think carefully about:
- pagination
- sorting
- filtering
- field selection
- summary vs detail views
A lightweight response is easier on:
- the database
- the application
- the network
- the client consuming the API
High-traffic APIs benefit enormously from disciplined response design.
5. Avoid doing slow work inside the request cycle
One of the fastest ways to make an API feel slow is to make every request do everything immediately.
That includes work like:
- sending emails
- generating reports
- calling slow third-party services
- processing uploads
- syncing with external systems
- building exports
- complex notifications
Not all of that belongs inside the request-response cycle.
This is where queues and background jobs become a scaling tool, not just an architecture feature.
A good rule of thumb is:
- if the user needs the result immediately, keep it in the request
- if the user only needs confirmation that the work has been accepted, move it to a queue
That keeps the API responsive while still letting the heavier work happen reliably in the background.
In a high-traffic system, this can make a dramatic difference.
6. Be careful with database access patterns
Many API performance problems are really data-access problems.
At low traffic, inefficient queries are annoying.
At high traffic, they become expensive very quickly.
Things to watch for:
- repeated queries inside loops
- loading too many rows
- fetching full records when only a few fields are needed
- poor pagination strategy
- unnecessary write operations
- too much per-request database work
The goal is not to make every query “perfect.”
It is to make database access deliberate.
That means:
- understanding what each endpoint needs
- querying only what is necessary
- avoiding repeated work
- using indexes appropriately
- designing endpoints so they do not encourage wasteful query patterns
If one endpoint is getting a lot of traffic, improving its query behavior often has a much bigger impact than adding more application servers.
7. Use caching deliberately, not blindly
Caching is powerful, but it is not magic.
A common mistake is to treat caching as a fix for unclear application behavior.
In reality, caching works best when you already understand:
- what changes often
- what changes rarely
- what is expensive to compute
- what needs to stay fresh
- what can tolerate a stale response
Good caching candidates often include:
- public read-heavy endpoints
- configuration-like data
- frequently requested reference data
- expensive computed summaries
- aggregated metrics that do not need second-by-second precision
Poor caching candidates usually include:
- highly personalized data without a clear invalidation model
- rapidly changing data that must be exact
- endpoints whose output shape is unpredictable
The most important thing is not “add cache.”
It is:
know why this data is safe and useful to cache
That is what keeps caching from creating correctness problems later.
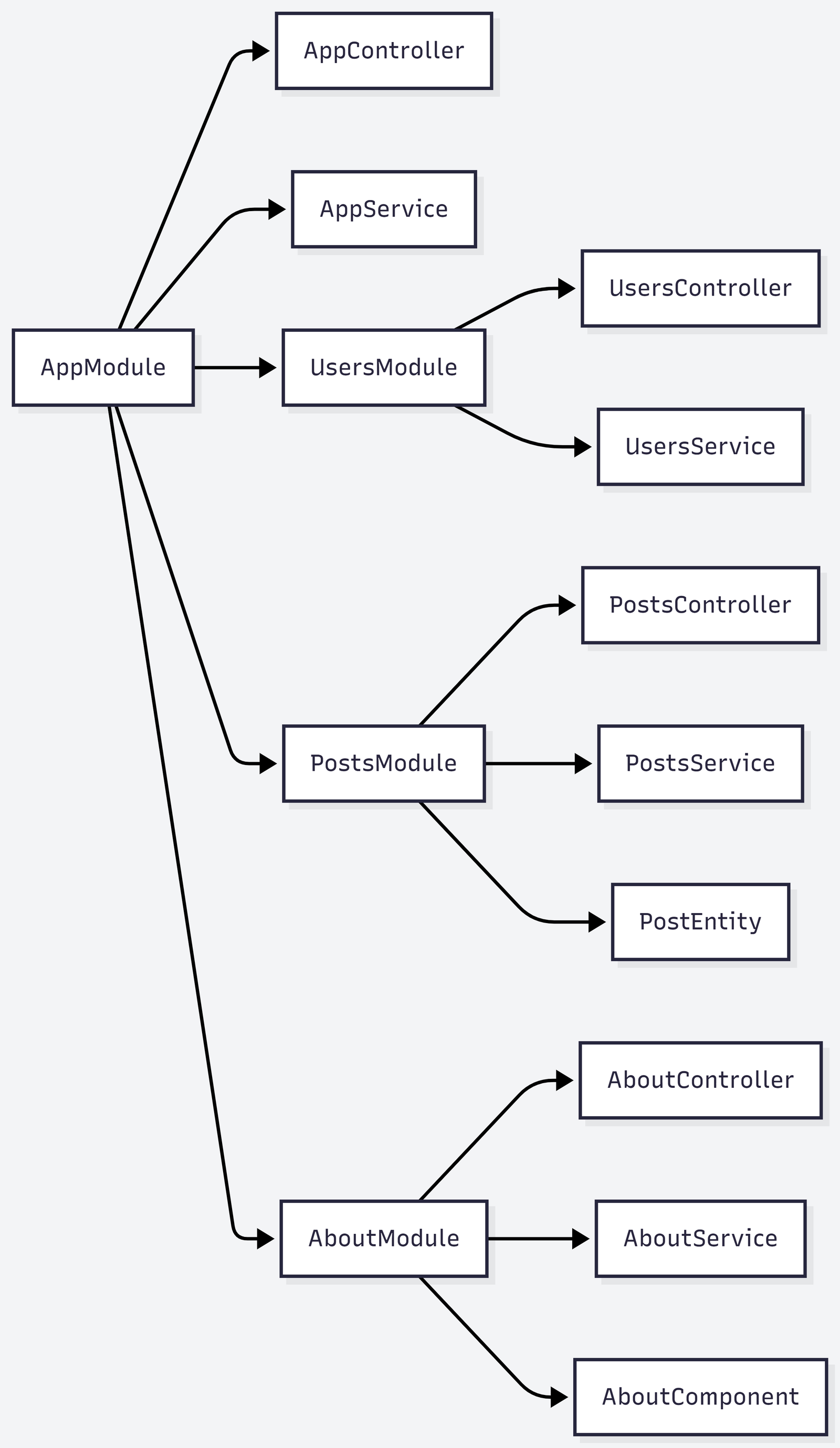
8. Design modules around real boundaries
Under load, poorly organized applications become harder to improve.
If features are tangled together, a change for one endpoint can affect several others in unexpected ways.
That is one reason modular architecture matters for scaling.
Modules give you:
- clearer ownership
- better isolation
- easier reasoning about hot paths
- safer refactoring as traffic grows
When modules reflect real feature boundaries, you can optimize or extend one area of the system without dragging the entire app with it.
For example, a busy Orders or Notifications area should not feel buried inside a generic “services” folder with everything else.
You want boundaries that help you answer questions like:
- where does this behavior belong?
- what part of the app is under load?
- what can be optimized independently?
- what can move to a queue or cache layer?
That is one of the quiet scaling benefits of good architecture.
9. Make docs and contracts part of performance work
At first glance, docs might not sound like a scaling concern.
But contract clarity has a real effect on high-traffic systems.
Why?
Because poor contracts create waste:
- clients over-request data
- clients misuse endpoints
- frontend apps retry in the wrong ways
- integrations send invalid or unnecessary payloads
- teams build around assumptions instead of documented behavior
Clear API contracts reduce confusion, which reduces misuse, which reduces waste.
This is where generated docs, OpenAPI, and client generation become more than convenience features.
They help keep consumers aligned with the actual shape of the API.
The better clients understand the API, the fewer accidental performance problems they create.
10. Watch the hot paths first
Not every endpoint deserves the same level of optimization.
Some routes matter far more than others.
A common mistake is trying to “optimize the whole app” instead of identifying the hot paths.
A better approach is:
- find the endpoints receiving the most traffic
- find the ones with the highest latency
- find the ones that do the most expensive work
- improve those first
This is where good structure helps again.
If your app is organized cleanly, it is much easier to inspect and improve the parts that matter most.
In practice, a small number of endpoints usually account for a large share of the load.
Improve those first.
11. Keep write operations intentional
Read-heavy APIs and write-heavy APIs scale differently.
When writes grow, small inefficiencies become more expensive because they often involve:
- validation
- persistence
- side effects
- notifications
- audit logging
- downstream integrations
That means write endpoints should be especially intentional about:
- what happens synchronously
- what happens asynchronously
- what must be persisted immediately
- what can be deferred safely
For example, creating a record may need to happen immediately, but:
- sending the welcome email
- updating analytics
- notifying another system
- building an export entry
may not.
Separating “must happen now” from “can happen after” is one of the most useful habits for scaling write-heavy APIs.
12. Prefer predictable patterns over clever shortcuts
As traffic grows, clever shortcuts become harder to trust.
One-off patterns, surprising file locations, and inconsistent endpoint behavior all increase the cost of maintenance.
A scalable API is not only fast.
It is also predictable.
That means:
- similar features are structured similarly
- validation happens in familiar places
- services behave consistently
- route organization stays clear
- response shapes are deliberate
Predictability makes it easier to:
- debug incidents
- onboard contributors
- profile behavior
- refactor safely
- scale with less friction
This is one of the biggest long-term benefits of framework discipline.
13. Scaling starts before the traffic arrives
One of the most important mindset shifts is this:
scaling is easier when the app was designed for change before the traffic spike happens
If you wait until the API is already under pressure, the fixes become more stressful.
If the app is already structured well, you have better options.
That does not mean building for massive scale on day one.
It means avoiding habits that make scale harder later.
Good scaling preparation is usually simple:
- keep controllers thin
- use DTOs and validation
- isolate business logic
- organize features by module
- move slow work to queues
- keep database access deliberate
- make contracts explicit
Those are not “enterprise extras.”
They are practical habits that keep growth manageable.
Where Assegai helps
Assegai is well suited to this style of thinking because its structure already nudges you toward the patterns that make scaling easier:
- modules create feature boundaries
- controllers keep transport logic separate
- providers/services give you optimization boundaries
- DTOs keep request contracts explicit
- queues help move expensive work off the hot path
- docs and generated clients help consumers use the API correctly
That does not mean the framework magically scales an app for you.
No framework can replace good design.
But a framework can make good design easier to sustain, and that matters a lot once traffic increases.
Final thought
Scaling high-traffic APIs is not just about infrastructure.
It is also about building an application whose structure allows you to improve the right things without chaos.
The best-performing systems are often not the ones with the most clever code.
They are the ones where the work is clear, the boundaries are strong, and the expensive parts are easy to identify.
That is what makes an API easier to optimize.
And that is why the best practices for scaling are often the same best practices for building the app well in the first place.
When the architecture is clear, scaling stops feeling like panic.
It starts feeling like engineering.